
En este artículo vamos a tratar un tema que quizás se pase por alto en muchas ocasiones: los datos estructurados en el SEO. Se trata de un asunto al que no se le presta demasiada atención, pero que puede tener multitud de beneficios, más allá de la aparición en las funcionalidades especiales de búsqueda de Google.
Como agencia SEO, en MKT Medianet estamos constantemente investigando para mejorar, y los datos estructurados son un tema complejo e interesante. Pero empecemos por el principio…
¿Qué son los datos estructurados?
En la ciencia de datos, los datos se pueden categorizar en dos tipos:
- Datos no estructurados: son piezas de información que no están organizadas de una manera predefinida: un texto, una imagen, un video, un sonido, etc. Esto los hace más difíciles de buscar y analizar por las máquinas.
- Datos estructurados: son piezas de información que sí tienen una organización predefinida por un lenguaje, lo que permite a las máquinas entender mejor su significado. Son fáciles de buscar y analizar.
Esto tiene su aplicación en el mundo de la web: existen determinados lenguajes que nos permiten marcar el contenido de las webs con datos estructurados, de modo que las máquinas puedan comprender mejor ese contenido.
Schema.org y semántica
Uno de esos lenguajes es Schema.org. Más concretamente, Schema.org es un vocabulario, es decir, un conjunto de términos que nos permiten nombrar y categorizar distintos elementos de las páginas web mediante datos estructurados. Schema.org fue creado en 2011 por Google, Bing y Yahoo con la intención de “crear, mantener y promover esquemas para datos estructurados en Internet”. Además, a finales de ese mismo año se unió también Yandex. Por tanto, se trata de un vocabulario aceptado por los principales motores de búsqueda.
Para entender cómo analizan los buscadores la información, es importante entender la noción de triple semántico. En Schema.org, cada fragmento de información se almacena en forma de triples semánticos, que son conjuntos de tres entidades que constituyen una declaración bajo la forma de sujeto-predicado-objeto (ID, propiedad, valor). Así, por ejemplo, la frase “Ramón sabe inglés” la podemos “traducir” a Schema.org de la siguiente forma:
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "Person1",
"name": "Ramón",
"knowsLanguage": “en”
}
En este caso, el ID es “Person1”, y las propiedades son “name” y “knowsLanguage” y los valores son “Ramón” y “en”.
Este formato facilita mucho la tarea de recuperación y análisis de la información a los motores de búsqueda.
Otra forma de entender esto es usando la teoría de grafos, que es una estructura matemática usada para describir las relaciones entre objetos. Según esta teoría, los grafos están formados por nodos o vértices conectados por enlaces o vínculos. En los datos estructurados, usamos los enlaces para describir relaciones entre nodos. En el caso anterior, tendríamos dos nodos, que serían “Ramón” y “en”, conectados por la relación “knowsLanguage”.
JSON-LD: los datos enlazados
Existen tres formatos principales que podemos usar para marcar una web con el vocabulario Schema.org:
- JSON-LD
- Microdatos
- RDFa
Vamos a obviar los dos últimos, ya que desde hace años no suele recomendarse su uso, y nos vamos a centrar en el primero.
JSON-LD significa JavaScript Object Notation-Linked Data. Es decir, usaremos las bases de JSON, el lenguaje de JavaScript para definir objetos, y gracias a los IDs de Schema.org podremos enlazar los datos.
Imaginemos que tenemos una página marcada con dos tipos de Schema.org: Organization y BlogPosting. Organization estará describiendo a la organización propietaria de la web y BlogPosting está describiendo un post de un blog. Si usamos el validador de marcado de Schema.org veremos que nos devuelve lo siguiente:
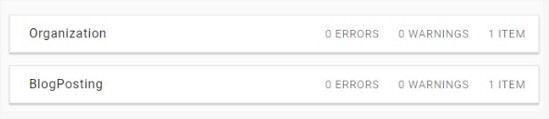
Pero esto, semánticamente, puede ser confuso para un motor de búsqueda, ya que no sabrá cuál es la principal entidad sobre la que se está hablando en la página. Considerará que ambas tienen la misma importancia.
Sin embargo, gracias al vocabulario Schema.org y a las posibilidades que aporta JSON-LD, podemos usar los IDs para anidar uno de estos marcados en el otro, y así definir una relación de dependencia entre ellos.
En este caso, si la página que queremos marcar es un post, la principal entidad que estaremos definiendo será de tipo BlogPosting. Schema.org tiene varias posibilidades para definir la relación entre estas dos entidades, pero la más normal sería “author”, para describir quién es el autor del post. Así, podríamos definir la relación con un código como el siguiente:
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"@id": "blog",
"author": {
"@id": "Organization"
}
}
Simplemente tendríamos que asegurarnos de que estamos usando aquí los mismos IDs para las entidades BlogPosting y Organization que en los bloques que ya tenemos marcados en la página. Y de esta forma estaríamos anidando el bloque de Organization dentro del de BlogPosting, y además estaríamos dejando claro cual es la relación semántica entre ambos.
Si después de esto volviéramos a validar los datos marcados en la página, veríamos lo siguiente:

Es decir, un solo bloque. Pero al pinchar en él veríamos que dentro tiene anidado el bloque de Organization, bajo la propiedad “author”.
Esta técnica nos permite ser mucho más claros, evitar duplicidad en los datos, identificar los nodos sin ambigüedades y activar las referencias externas (es decir, podríamos hacer referencia a un ID de otra página, incluso de otra web, aunque esto aun no lo reconocen los motores de búsqueda).
Ventajas del marcado de datos estructurados para el SEO
Una vez conocemos cómo funcionan los datos estructurados y para qué sirven, podemos pasar a las principales ventajas que nos aportan en el ámbito del SEO.
Como hemos comentado de pasada al principio, en el mundo del SEO se presta atención a los datos estructurados sobre todo cuando pueden generar funcionalidades especiales en los resultados de búsqueda. Podemos ver en qué casos se puede producir esto en la Galería de datos estructurados de Google. Pero los más comunes son los siguientes:
- Artículo: permite aparecer como una noticia destacada en la búsqueda de Google.

- Ruta de Exploración o Migas de Pan: permite que Google muestre la posición en la que está tu página web dentro de la jerarquía del sitio web.
- Preguntas frecuentes: permite a Google mostrar parte de tu contenido en su formato de preguntas frecuentes.
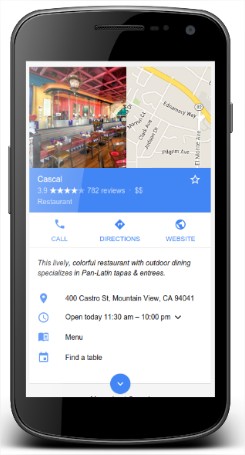
- Empresa local: permite a Google mostrar el panel de información con detalles sobre la empresa o aparecer en un carrusel con otras empresas.
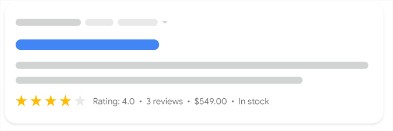
- Producto: permite a Google mostrar información del producto en sus resultados de búsqueda de una forma más completa (precio, disponibilidad, valoraciones de los usuarios, información de envío, etc.).
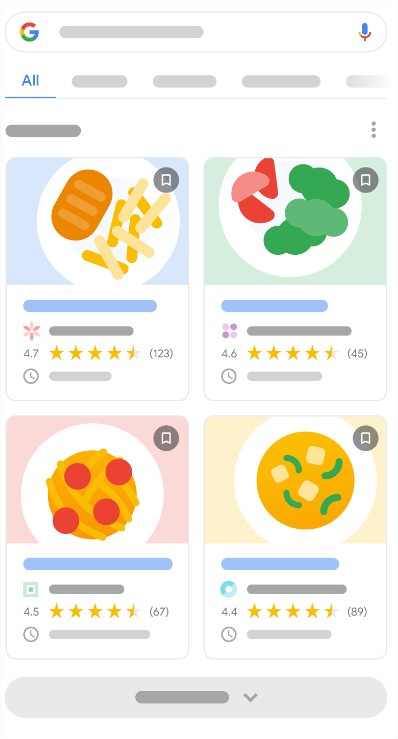
- Receta: permite a Google entender mejor la receta y presentarla a los usuarios de forma que les interese.
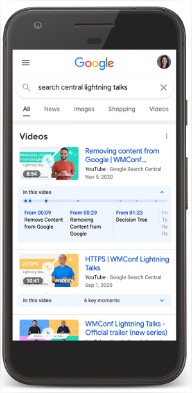
- Video: permite a Google entender mejor ciertos datos relacionados con un video, lo que aumenta las probabilidades de que aparezca en un resultado de búsqueda especial.
Para que una página sea seleccionable para aparecer como alguno de estos resultados enriquecidos, tenemos que seguir las directrices de Google, que define, para cada tipo de datos, unos campos obligatorios y otros recomendados. De ahí la importancia de usar tanto el validador de Schema.org, como la prueba de resultados enriquecidos de Google. Pero hay que tener en cuenta que estas herramientas no sirven para lo mismo: mientras que la prueba de resultados enriquecidos solo reconocerá aquellos datos estructurados que puedan activar alguno de los tipos de datos que activan funcionalidades especiales en la búsqueda (los que aparecen en la galería de Google que hemos comentado antes), el validador de Schema.org reconocerá cualquier tipo de datos estructurados marcados con ese vocabulario. De esta forma, por ejemplo, si marcamos una página con el tipo de Schema “Service”, el validador de Schema.org nos lo mostrará, pero la prueba de resultados enriquecidos de Google no.
Pero como hemos comentado durante todo este artículo, los beneficios de usar los datos estructurados en SEO van más allá de aparecer en los resultados enriquecidos de los buscadores. Gracias a los datos estructurados, podemos organizar semánticamente nuestras páginas web, definir cuales son las principales entidades en cada página, establecer relaciones entre esas entidades y aportar más información y contexto. Todo esto puede ayudar a los motores de búsqueda a comprender mucho mejor nuestros contenidos, y eso siempre puede significar una mejora en los rankings.